
Credible [software and source code]
Kault, David (2017) Credible [software and source code]. James Cook University, Townsville, QLD, Australia.
![[img]](https://researchonline.jcu.edu.au/style/images/fileicons/other.png) |
Other (Software: Executable file)
Available under License GNU GPL (Software). Download (612kB) |
|
![[img]](https://researchonline.jcu.edu.au/47395/5/scrnsht.gif)
|
Image (GIF) (Screenshot: Program window)
Download (33kB) | Preview |
|
|
Other (Source code: Fortran 90 file)
Restricted to Repository staff only |
|
![[img]](https://researchonline.jcu.edu.au/style/images/fileicons/text_plain.png) |
Plain Text (Parameters for Fortran 90 file)
Download (49kB) |
{kind=link}

Abstract
The "credible" program is a calculator which processes conventional statistics to improve estimates of relative risks. To install "credible" (windows only), download the executable file (setupcrediblec.exe) and then click on it. This installs the program "credible" and its required parameter file. Also downloadable are the source code (credallfortran.f90) and parameters (credparams.txt). Those who wish to avoid downloading an executable or who wish to modify the program, can download the Fortran 90 file. The parameters must then be downloaded to the same folder as the Fortran 90 file. The source code can then be compiled with a Fortran compiler to give a command line version of the program that can run on any operating system (MS-DOS, Linux, Mac). A Linux version of the compiled program is available on request to: David.Kault@jcu.edu.au.
The following text is included in a MoreInfo window as part of the program. It provides a summary of the ideas behind the calculation and the circumstances in which they can be applied:
REPLACING p-VALUES and CONFIDENCE INTERVALS with OBJECTIVE PROBABILITIES and CREDIBLE INTERVALS
Someone naive to medical statistics would expect a p-value to mean “the chance that the apparently favourable results in a trial of a new treatment are due to chance”. Similarly they would expect a 95% confidence interval to mean that “the true amount of difference made by the new treatment has a 95% chance of being somewhere in the given range”. Sadly, such expectations are incorrect as the following two examples show:
p-VALUES: Consider two separate trials of treatment A versus standard treatment in one trial and treatment B versus standard treatment in the other trial, with both trials being for the same disease. Now consider what we should think about these treatments if, coincidentally, they both gave the same mildly favourable results. They would then both give the same p-value. However treatment A might be based on the best medical science and treatment B might be the placement under the patient's pillow of an amethyst crystal blessed by the Great Popuff. Common-sense tells us that despite the equal p-value, it cannot be true that both treatments are equally likely to be effective.
The correct interpretation of p-values is that they are the probability of getting results at least as suggestive of a real effect as the results to hand, when in fact there is no real effect and the outcome is entirely due to chance. If chance can “quite easily” explain the outcome, the effect is said to be “not significant”, otherwise it is “significant”. In this context, “quite easily” refers to any chance that is more probable than 1/20 or 0.05 .
95% CONFIDENCE INTERVALS: Consider a person who wants to establish a 95% confidence interval for the height of men, but who is lazy and types into the computer just two heights he has measured – 160cm and 180cm. A computer package will then calculate that we can be 95% confident that the average height of men is between 43cm and 297cm – but clearly we have 100% certainty, not 95% probability, that average height is in this range.
The correct interpretation of 95% confidence intervals for the true amount, is that they are a range of values readily compatible with the data. The ready compatibility is determined by a criterion related to a p-value of 0.05
We see that in calculating p-values and confidence intervals, traditional or frequentist statistics doesn't give us the probabilities we want. Traditional statistics cannot use the data to tell us the “chance that it is chance” or give a 95% probability range for an amount, because probability calculations in the light of data have to be built on probabilities prior to knowing the data. Bayesian statistics takes a different approach and uses prior probabilities to calculate the relevant probabilities. However, prior probabilities have been little used in medicine so traditional statistics leaves us with p-values and confidence intervals which have only a tangential and partial connection to what we would want them to mean. Prior probabilities are little used in medicine because it was assumed that they would be based on expert opinion and even the best experts can be biased, or even corrupted by commercial interests. Instead traditional statistics lets the data “speak for itself” but that has meant we have been left with p-values and confidence intervals and their indirect and partial relationship to what we want to know about a treatment.
Now however a method has been developed of obtaining objective prior probabilities about medical treatments. The method was explained in a paper by D Kault & S Kault published in PLOSOne in November 2015 entitled “From p-values to objective probabilities in assessing medical treatments”. The ideas in this paper have now been extended to the calculation of credible intervals to replace confidence intervals. The extended method was published (initially online) in “Evidence-Based Medicine” (ebm.bmj.com) in January 2017 as “The Maimed Martian, credible intervals and bias against benefit” (DOI: 10.1136/ebmed-2016-110539). These credible intervals have a number of advantages over confidence intervals – they tend to be shorter, they allow for publication bias and importantly, there is a 95% chance that the value of interest lies in the 95% credible interval.
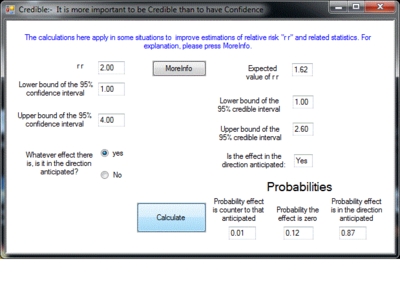
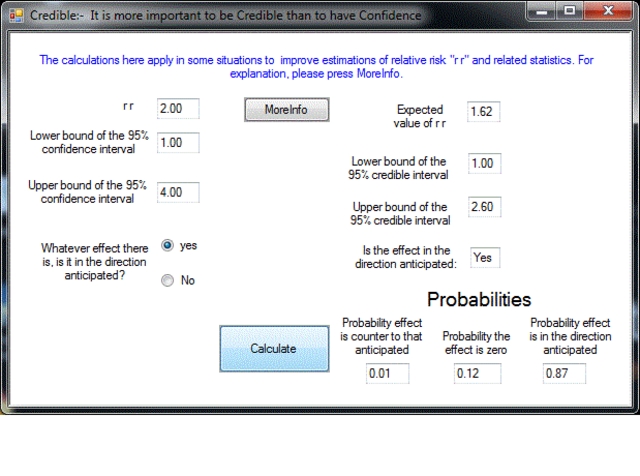
To accompany the publication in Evidence-Based Medicine, this program “credible” is being distributed. Type into “credible” a relative risk and its 95% confidence interval and out will come the 95% credible interval together with some other measures, such as the probability that the treatment has some positive effectiveness.
The program “credible” applies in a somewhat restricted set of circumstances. Full details are given in the PLOSOne article but the main restrictions are as follows:-
1) The outcome is expressed as a relative risk, hazard ratio or odds ratio together with the confidence interval. All such statistics are for simplicity abbreviated as “r r”. (The statistical theory commonly used in confidence interval calculations for r r's, results in a lognormally distributed confidence interval in which the geometric mean of the confidence interval bounds is the r r measure. “Credible” is not calibrated for use on statistics where this is not true. Credible checks this requirement and gives a warning if it is not met.)
2) The clinical trial has to be of the form of a comparison of a standard treatment plus an additional treatment in one arm versus a standard treatment in the control arm. In a trial of this form it can be anticipated that the effect of the additional treatment, if any, is more likely to be in a positive rather than negative direction. A positive direction may be shown by a relative risk less than 1.00 (as in a decreased risk of dying with the additional treatment) or shown by a relative risk greater than 1.00 (as in an increased “risk” of someone trying an anti-smoking aide being successful in giving up smoking). Before proceeding with the calculation, the “credible” program therefore requires an answer to an additional question “Is the relative risk in the direction anticipated?” Occasionally there is an extra negative in this process that needs to be considered. - a trial may be of a comparison between a standard treatment and, for cost saving purposes, a treatment regime that omits some component of the standard treatment. In such a case, the anticipated effect would be in the direction favouring the full standard treatment – though if this was convincingly the result, it would be disappointing for those conducting the trial.
3) The third requirement is that the clinical trial does not involve commercial interests – new drugs or devices under patent.
4) The trial also has to be of sufficient quality that would make it eligible to be analysed in a Cochrane review.
The prior probabilities used by “credible” are objective in that they are not based on expert opinion. Instead, they are based on an estimate of what may be called an “effectiveness distribution” as determined by analysing a random sample of statistics from the Cochrane Collaboration. This effectiveness distribution is calculated after making allowance for publication bias. “Credible” uses this effectiveness distribution together with the summary statistics from a clinical trial or meta-analysis and gives the probabilities that the treatment has positive or zero effectiveness and the probability that it is counter-productive. It also gives the shortest interval which has a 95% probability of containing the true value – the 95% credible interval. As well, “credible” also calculates a single best estimate for the true value of r r. This estimate takes into account the actual value obtained, the accuracy with which it was measured as indicated by the confidence interval and the appropriate adjustment in the light of the “effectiveness distribution”. This best guess is termed the “expected r r” and is the first figure given.
If this work was repeated based on prior probabilities from a different random sample from Cochrane, slightly different results could be obtained. For accuracy, in quoting the probabilities obtained from “credible”, the prior effectiveness distribution should, at least implicitly, be specified. It is suggested that perhaps the credible intervals obtained with this software should be termed “MM credible intervals”, after the Maimed Martian in an anecdote in the 2017 paper which described their calculation.
A Linux version and/or the source code for “credible” is available on request to: David.Kault@jcu.edu.au David Kault (MBBS, BSc, PhD) College of Science and Engineering, James Cook University, Qld, Australia
| Item ID: | 47395 |
|---|---|
| Item Type: | Other |
| Keywords: | credible intervals, Bayesian statistics, false negative results, publication bias |
| Related URLs: | |
| Additional Information: | Credible: Copyright (C) 2017 David Kault. This program may be distributed freely under the terms of the GNU Public License https://www.gnu.org/licenses/gpl-3.0.en.html Supporting publications are available from the Related URLs links below: Kault, David (2017) The maimed Martian, credible intervals and bias against benefit. Evidence-Based Medicine. (In Press) This publication contains the extended method including the calculation of credible intervals to replace confidence intervals. Kault, David, and Kault, Sam (2015) From p-values to objective probabilities in assessing medical treatments. PLoS ONE, 10 (11). pp. 1-19. Outlines methods for obtaining objective prior probabilities about medical treatments. |
| Date Deposited: | 13 Mar 2017 02:15 |
| FoR Codes: | 01 MATHEMATICAL SCIENCES > 0104 Statistics > 010402 Biostatistics @ 100% |
| SEO Codes: | 92 HEALTH > 9202 Health and Support Services > 920204 Evaluation of Health Outcomes @ 100% |
| Downloads: |
Total: 172 Last 12 Months: 6 |
| More Statistics |
Actions (Repository Staff Only)
 |
Item Control Page |